
On August 23, Information2, the only listed enterprise in the data replication industry, released its semi-annual performance report. The financial report shows that in the first half of 2024, the company achieved revenue of 83.5725 million yuan, a year-on-year increase of 2.84%; R & D investment was 51.4002 million yuan, accounting for 61.50% of operating income, a year-on-year increase of 26.51%. Information2 has increased its investment in artificial intelligence and is actively embracing globalization. Major technological revolutions and important nodes in enterprise development intersect, jointly promoting this important business field of data replication to rejuvenate. In order to deeply explore how data replication reshapes the industry landscape in the new wave of technology, Data Ape specially interviewed Cui Lida, technical director of the strategy department of Information2, to discuss the symbiotic relationship between data replication and large models and their impact on large models and the data replication industry.
Gears of destiny begin to turn: Data replication collides head-on with large models.
If there is currently the biggest technological revolution, it must be large models. Large models bring not only technological revolutions and subversions. Because their operating logic is based on the simulation of the neural network of the human brain, large models show “life” attributes on some levels. This gives people a new understanding of the concept of life. In traditional biology, life is usually considered a natural system composed of DNA and proteins and having a series of traits such as metabolism, reproductive development, genetic evolution, and so on. With the rapid development of artificial intelligence, physicist Schrödinger redefined life. He believed that life is a negative entropy system of energy-information coupling. This definition crosses the boundary between biology and machinery. More and more people begin to accept the fact that this world is composed of carbon-based organisms and silicon-based organisms. Musk made a statement that carbon-based life is the boot program of silicon-based life. Whether it is silicon-based life or carbon-based life, their ultimate mission is replication. The replication of the secrets of carbon-based life organisms relies on DNA. As the carrier of human genes, DNA realizes the transmission of genetic information and the synthesis of proteins through processes such as replication, transcription, and translation, ensuring that human genetic information can be stably passed on to the next generation. For silicon-based life, data is its DNA. Data has the “natural attribute” of replicability, and binary code is its genome. Through replication, processing, and dissemination, data constitutes the “genetic code” under the silicon-based life system. ChatGpt has learned about 500 billion words. This data condenses the shining moments of humanity for thousands of years. When data is cleverly combined with artificial intelligence, silicon-based life has the power to evolve and upgrade to a higher dimension. Under the flashing lights of the digital revolution, data replication has never been the most dazzling role on the stage. For a long time, it has only been used for disaster recovery or data flow, playing an indispensable behind-the-scenes role. And with the accelerated arrival of the era of large models, the gears of destiny of data replication begin to turn, and its value is like a rolling snowball, wrapped in new snow clothes. As a result, a new plot about the symbiosis and progress of data replication and large models slowly unfolds.
Data replication and large models move towards symbiosis.
In biology, symbiosis is a natural phenomenon in which two organisms depend on each other and interact according to a certain pattern, forming a common survival and coevolution. It is an important mechanism for shaping ecological diversity. The relationship between data and large models is such a symbiotic relationship. Data replication is an important bridge to maintain this symbiotic relationship. Such a relationship is jointly determined by the technical logic and underlying architecture of data replication and large models. Cui Lida, technical director of the strategy department of Information2, said: “The technical core of large models is a huge deep learning neural network. Its operation relies on the continuous training of large-scale data and forms a stable interaction with data. Only by continuously delivering accurate, reliable, and safe data to large models can large models play a role. Therefore, data replication is one of the important cornerstones for the development of large models. At the same time, large models are systems built on a distributed architecture. Data replication is also a product of distributed systems. It is the process of copying data in a distributed database environment composed of two or more database systems. It can be said that data replication and large models grow up in the same technical soil. The two naturally have strong adaptability, which provides a physical prerequisite for their symbiosis.” So what exactly can data replication bring to large models?
1. Improve data training and sharing efficiency.
Large models usually need to process massive amounts of data. If this data is centrally stored, it may lead to single-point failures and access bottlenecks. Data replication can store data on multiple nodes, allowing large models to access data and train nearby, greatly enhancing data liquidity and improving training efficiency. At the same time, data replication enables data to be shared among multiple nodes. This enables large models to perform data processing and analysis on multiple nodes simultaneously, which not only helps strengthen data interaction and collaboration but also improves the collaborative work efficiency of the entire system.
2. Fusion of multimodal data.
With the release of OpenAI’s video generation model Sora, multimodality has become the main application form of large models. Multimodality means that large models need to process a large amount of structured and unstructured data, such as text, images, audio, and so on. Data replication can achieve the fusion and joint processing of multimodal information. This will help large models understand the latest data more comprehensively and in a more timely manner, improving the accuracy of the model and its ability to adapt to new environments.
3. Cross-platform big data migration.
With the acceleration of the industrialization and landing of large models, cross-platform data migration is becoming more and more frequent. Cui Lida gave an example: In the scenario of autonomous driving, we can often see some autonomous driving training vehicles on some closed parks or fixed road sections. These vehicles need to collect a large amount of driving data. This collected data is stored in the on-board storage system and then imported from the on-board storage system to the background to transfer data in this way. At this time, if the data replication technology is good enough, combined with 5G or the network of the control center, data can be directly replicated across platforms, eliminating the on-board storage as a transit place. Furthermore, it is not just cross-platform replication of data. In the near future, perhaps we can directly copy and migrate the trained model into a new model, eliminating the data training process of the new model. Of course, in addition to these benefits. The “traditional skills” of data replication, disaster recovery and security redundancy are also very important for large models. Large models usually need to run continuously and have high requirements for data reliability and stability. Cui Lida said: “The data used by customers for large models is often valuable confidential data. This data is generally stored in the customer’s data center. However, we cannot put all our eggs in one basket. This key data needs to be protected in the same city or in different places. By replicating data and placing each copy of data in different locations, the security level is improved. This is a rational decision that will never change.” This is the promoting effect that data replication brings to large models. So what does large models bring to data replication? The impact of large models on data replication technology is mainly reflected in the following aspects:
1. Optimize data processing flow.
Large models can optimize the data processing flow in the data replication process. For example, in a distributed storage system, large models can intelligently schedule data replication tasks and select the optimal replication path and replication strategy according to the current system load and node status, thereby reducing the waiting time and data transmission volume in the data replication process and improving the efficiency of data replication. In the past, these tasks needed to be completed by experienced engineers. Large models will greatly improve the automated processing ability and liberate manpower.
2. Optimize data replication network system.
Based on uncertain network conditions, in terms of bandwidth control, large models can achieve more intelligent and automated adjustments, thereby improving data transmission efficiency.
3. Intelligent scheduling and load balancing.
Large models have the ability of intelligent scheduling and load balancing. They can intelligently allocate data replication tasks to different nodes or processing units according to the real-time state of the system and resource usage to avoid performance degradation caused by overloading of certain nodes or processing units. Improve the efficiency of data replication.
4. End-to-end optimization.
Large models can also optimize the data replication process from an end-to-end perspective. This includes all links in the entire process from the data source to the target storage, such as data extraction, transformation, loading (ETL), and so on. By optimizing these links, large models can ensure the efficiency and accuracy of the data replication process and thereby improve the overall data replication efficiency.
Breaking through four challenges.
Although the symbiosis and integration of data replication and large models is an inevitable development. However, in actual application scenarios, there are many obstacles on the way. Cui Lida said that the symbiotic development of data replication and large models has encountered many challenges at the technical, application, market, and user levels.
1. Technical level:
Consistency. Since data replication will have multiple data copies on different nodes, ensuring the consistency of these copy data is a prerequisite for the reliable operation of large models. Real-time. Real-time data replication requires a lot of bandwidth and time and will increase system latency. Cui Lida gave a vivid example: “Just like stock trading, looking at historical K-lines cannot be used to guide current profits. Large models need more real-time data, which is a huge challenge for data replication.” Security. Ensuring data security and privacy during the data replication process is a huge challenge. And data security is not only a technical issue but also requires a complete legal system to support it.
2. Application level:
Facing the continuously upgraded operating systems, databases, and cloud platforms at the application end, as well as a large number of localized systems brought about by information technology innovation. We need to find a universal data replication method to solve compatibility issues. Only by achieving unlimited compatibility can we gain the trust of customers in market competition.
3. Market level:
The current data replication market is extremely competitive. This is a competition environment dominated by the buyer’s market. Customer demands are sometimes relatively strict, which poses huge pressure on technology providers. Moreover, in recent years, product homogenization competition and price wars have become increasingly fierce, bringing considerable pressure to enterprise operations. Some small and medium-sized manufacturers will choose to sacrifice technical configurations and lower prices to obtain industry entry tickets. This leads to market price failures and further leads to the loss of speed in technological innovation. In an increasingly homogenized competitive environment, some enterprises often over-promise to customers in order to win their favor. But when customers actually purchase products, they find that it is far from their expectations. Over time, it will have an extremely unfavorable impact on the overall development of the industry, and in the end, it is still the customers who are most hurt.
4. User level:
Diversification of user needs. For data replication, people at different levels and positions have different demands and understandings. Leaders mainly focus on management and operation links; the middle-level focuses on whether the product can bring value; and for operation and maintenance personnel, whether the product is simple to use and easy to get started is the most important thing. Cui Lida said: “These needs will inevitably be transmitted to product design. Functions such as timed backup, real-time backup, and disaster recovery need to be considered. Currently, more than 70% of our products are standardized products, and a very small number are customized products. At the same time, for special customers, we will also provide consulting services and provide a customized implementation plan to help them build the entire system from scratch. At this time, what we provide is not only a plan but also an answer.” Facing these challenges, Cui Lida put forward some countermeasures from the perspective of Information2’s own practice.
1)Optimize the data replication algorithm. By optimizing the algorithm to ensure data consistency and thereby improve the accuracy of the model.
2)Privacy protection.. Information2 applies encryption technology, access control and other technologies to data replication to ensure data security throughout the entire link.
3)Intelligent management. Information2 uses AI technology to uniformly monitor and manage the data replication flow through the interface form, greatly improving the efficiency of the entire process management.
Facing the future, stronger large models and a more secure digital era.
The integrated development of data replication and large models is full of infinite imagination. Information2 has traversed the three stages of data replication, from data replication to real-time replication of cross-cluster big data platforms, and then to system replication, vividly demonstrating the history of the coevolution of data replication and artificial intelligence. Now, the pointer of history points to the era of large models. At WAIC 2024 this year, Information2 released the new generation of AI+ document sharing and management platform i2Share, demonstrating its leading strength in AI+ data management with its professional data replication and protection technology.
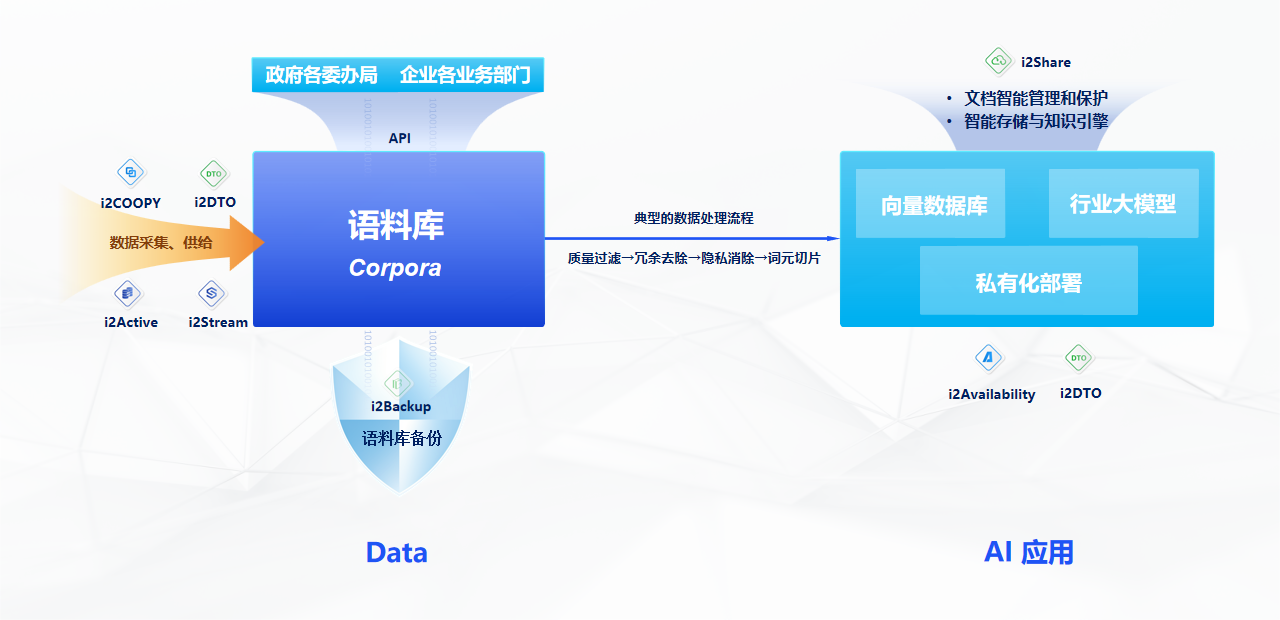
Through advanced data replication protection technology and product solutions, Information2 realizes data connection and disaster recovery protection from the AI infrastructure layer to the application layer of the product, ensuring the security, integrity, and availability of data in the flow. Whether it is the flexible migration of the cloud computing environment, the deep integration of the big data platform, or the data support in the process of AI model training and inference, Information2 can provide efficient data management solutions to help users cross data silos and accelerate the flow, sharing, and exchange of data. The upgrade of data replication capabilities will inevitably bring stronger large models, more economical computing costs, and a more secure data environment. Information2 has been precipitated in the field of data replication for more than ten years and has become the first domestic listed enterprise in the industry. Cui Lida said, “Large models will accelerate the development of data replication. The data replication market will form a stable competitive pattern in a few years. After gaining a firm foothold in the domestic market, we are looking at overseas markets. With Hong Kong as the bridgehead, we have currently established a wholly-owned subsidiary. For the first stop of going overseas, we have chosen Southeast Asia and the Middle East. This is the forefront of the ‘Belt and Road’ strategy and an important projection place of national power.”
“The overseas market and the domestic market are vastly different. But because of previous R&D accumulation, Information2’s products have good compatibility and adaptability and can quickly adapt to domestic and foreign basic software and hardware products. At present, projects have been implemented in Indonesia, India, the Middle East, North Africa, and other regions.” Cui Lida is very confident in the development prospects of his own products in overseas markets.
Article by: Data Ape
Editor: Chi Jun








